
Can ChatGPT Code Your Open-Ends? (And Which Ones?)
By Kevin Collins
Attention is a scarce resource, in politics as in life, and measuring it well is harder than it looks. We have been working to build what we call an "attention barometer": a way to gauge, in close to real time, which news stories are pressing on the public consciousness.
A good instrument for this task has three requirements:
It needs to be short, so it does not take up too much valuable survey time.
It cannot direct attention toward the very stories we are trying to measure.
It has to avoid the acquiescence bias that inflates reported attention when you simply read people a list and ask whether they were paying attention to each item.
That set of requirements points naturally toward an open-ended question. Ask people, in their own words, what caught their attention, and one can sidestep the priming and the yea-saying in one move. But there’s a catch: someone has to read and code every response, and that labor is slow and expensive. This is exactly the kind of task large language models are now being recommended for. So the question we set out to answer is a practical one: can an LLM code these responses quickly and reliably enough to make the open-end approach viable, and if so, under what conditions? This is the question we set out to answer in research we first presented at AAPOR’s 2026 Annual Meeting in Los Angeles.
Prior research suggests that frontier models can classify open-ends with reasonable accuracy (Rytting et al. 2023; Mellon et al. 2024; Soria 2025), but always with caveats. Accuracy tends to fall as the number of categories grows (Mellon et al. 2024). Fine-tuning may be required (von der Heyde et al. 2025). Performance varies by the difficulty of the coding task (Soria 2025), by language (Ashwin et al. 2025; Dahlberg et al. 2026), and by prompting strategy (von der Heyde et al. 2025). Coding open-ends about current events sits near the hard end of that spectrum. There are many categories, and they are not mutually exclusive. The events being described are contemporaneous, which means they may not exist in a model's training data at all. And the samples are small enough — ours is around 1,500 responses — that there is no spare data to fine-tune on. We added one further constraint of our own: we wanted to work through the chat interfaces that allow code execution (ChatGPT when we began, and now Claude as well) rather than through an API, because those interfaces are more transparent. The model tells you what it is doing instead of acting as a black box, and it generates python code which makes it replicable.
The Attention Barometer
The data here come from the first of our attention barometer surveys, fielded August 26 through September 1, 2025, with 1,449 non-null responses to the open-end. We fielded it across three modes in roughly equal shares: live interviewer interactive text, text-to-web, and panel-to-web (using sample from Cint). The full methodological details are available here. The instrument was short — 23 questions — and the barometer item came second, after a right-direction/wrong-direction warm-up. We asked:
In a few words, what news story caught your attention this week? "News" can be anything you follow, whether local TV, websites, podcasts, or social media, on any topic like sports, entertainment, or politics. We just want to know what caught your attention. If you can't think of anything specific, that's okay, just say so. Please reply in your own words.
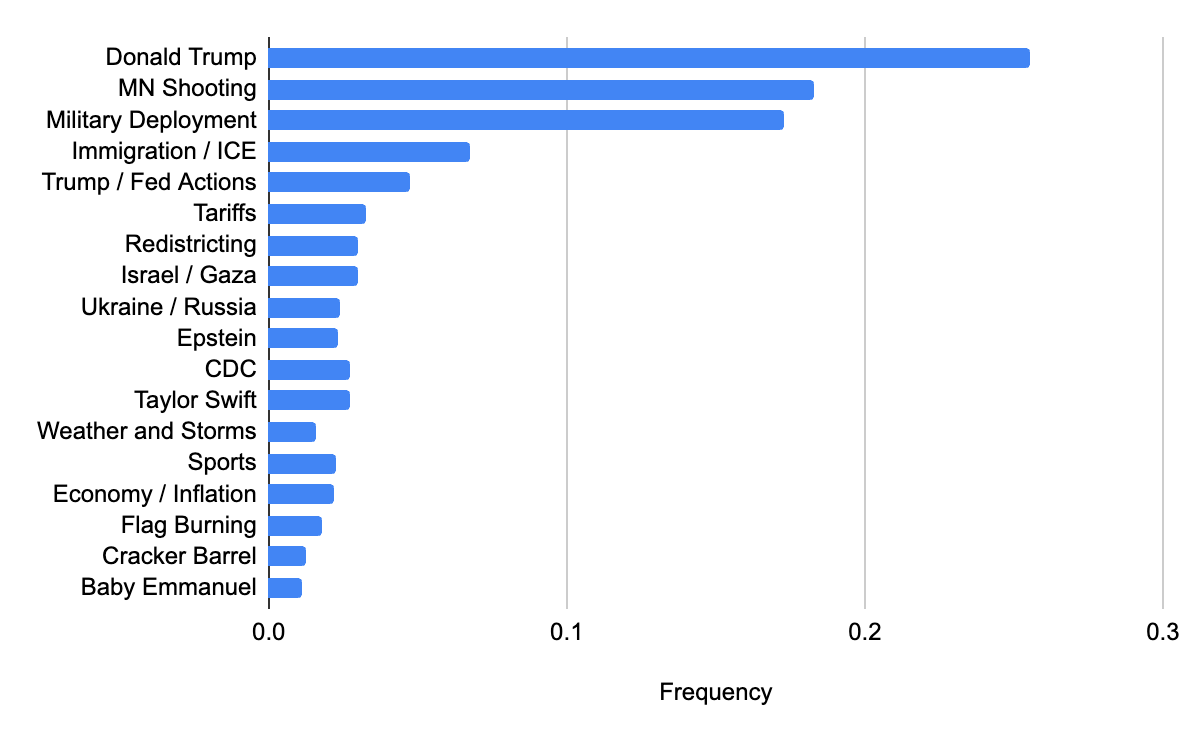
It was a busy week. We hand-coded the full set of responses into 18 categories, and the distribution gives a sense of the news environment: Donald Trump led, followed by the Minneapolis Catholic school shooting and the federal deployment of troops in Washington, then immigration and ICE, tariffs, redistricting, Israel and Gaza, and a long tail that ran from Epstein to Taylor Swift's engagement to the briefly redesigned Cracker Barrel logo.
What the models are actually doing
The most important thing we learned is also the simplest. When you ask ChatGPT to code a batch of open-ends, what it actually does is write a Python script that runs a keyword search, with varying degrees of sophistication. Claude does the same. This is worth underlining, because it is not the same thing as understanding the responses. The model is matching strings, and that fact shapes exactly when it succeeds and when it fails.
Reading the responses against the codes makes the failure modes concrete. There is the problem of where one category ends and another begins: is a school shooting in Minneapolis the same story as one in Missouri? Is the takeover of the DC police the same story as the deployment of the National Guard? There is the problem of people describing the same event in different words — "Minneapolis school shooting" and "transgender Catholic church shooting" are the same tragedy seen through different ideological perspectives. There is low specificity, where a respondent says "shooting" and could mean any of several that week. There are false positives, where a keyword appears in passing but is not the answer, as with the respondent who recited a litany of grievances about inflation and housing before concluding that what actually caught their attention was Taylor Swift and Travis Kelce. And there is the occasional word salad or answer to a question we did not ask. A keyword search has no way to adjudicate any of this.
How accurate, and for which categories
To put numbers on it, we compared each model's output against the hand codes, using F1 score as a summary measure of predictive accuracy. (Raw accuracy looks high across the board, but that is mostly because the vast majority of cells are true negatives; F1 is the more honest summary because it ignores true negatives and rewards getting both precision and recall right.) We compared three models: GPT-5 run contemporaneously the week after fielding, GPT-5.2 run roughly eight months later, and Claude Opus 4.7, also run later.
The GPT results are all over the map. Some categories score above 0.8; others fall below 0.5. When a category scores poorly, the problem is almost always recall rather than precision — the false positives are few, but the model misses real positives it should have caught.
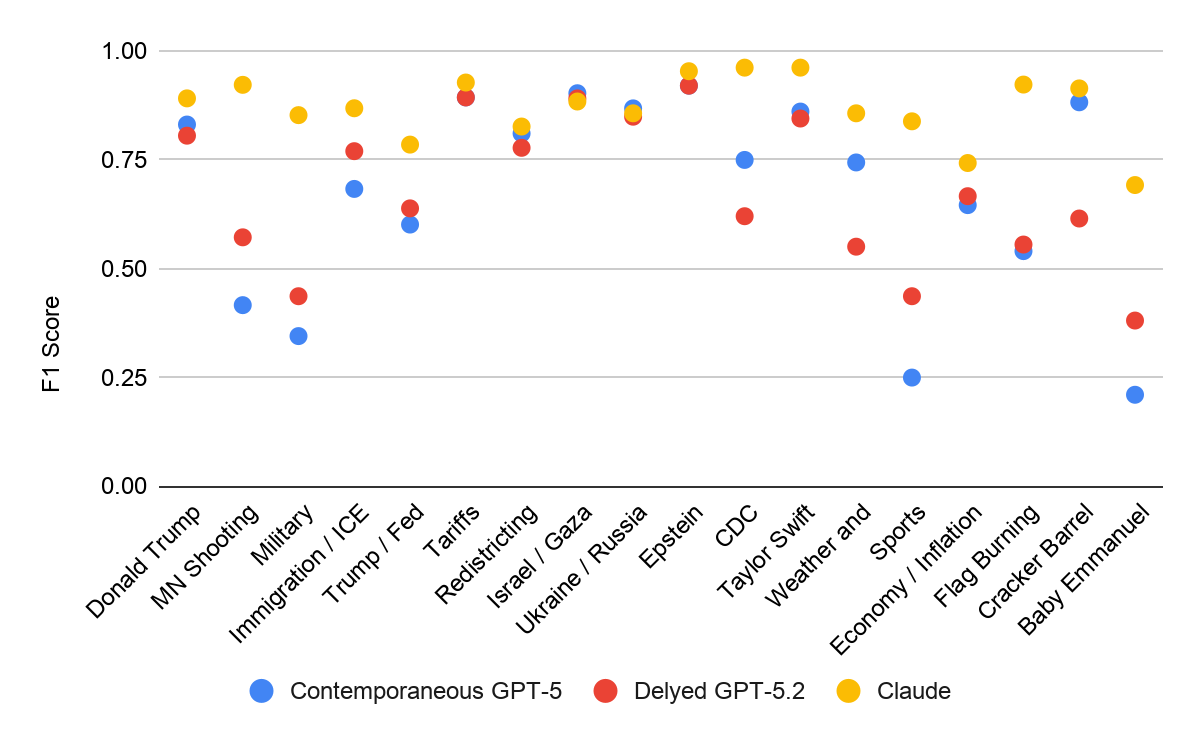
Claude performed more consistently and, on average, better. We report that as a finding, but we want to flag an important caveat rather than oversell it. The Claude run was not contemporaneous, so we cannot rule out the possibility that these news events were already in its training data, which would give it an advantage that would vanish in real-time use. Until we test contemporaneous Claude coding directly, the comparison across models is not apples to apples.
The pattern underneath the variation is telling, and it follows directly from the keyword-search mechanism. Categories anchored in proper names — people, countries, a country-themed restaurant chain — are coded much more accurately than categories defined by more diffuse, conceptual language. For the GPT models the gap is large; for Claude it is present but smaller. This is the central limitation in one line: the models are good at the categories that have a stable, shared vocabulary, and weaker on exactly the kinds of categories where respondents reach for their own words.

Which responses get coded well
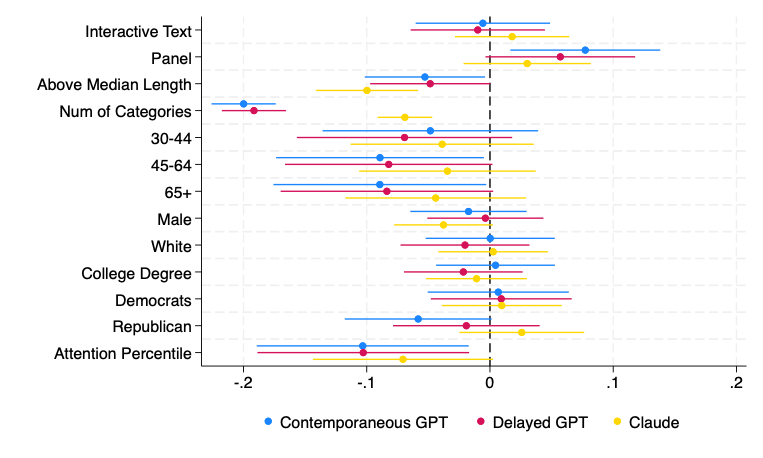
Looking at accuracy response by response, and regressing it on features of the response and the respondent, sharpens the picture further. Responses from online panelists were coded more accurately, perhaps because panelists are socialized into a particular way of answering, though we have not pinned down the mechanism. Longer responses and responses that named multiple categories were coded less accurately, which raises real questions about question design. And we found lower accuracy for older respondents and, in some models, for Republicans, though those estimates are imprecise. More concerning, responses from the most politically attentive respondents were coded less accurately, and this held even after controlling for length and other factors. We do not yet understand why, but anything that makes coding accuracy correlate with political attention is a potential source of bias we will want to chase down.
What we take from this
Our reading is cautious. ChatGPT or Claude will code your open-ends if you ask them to, but what they are really doing is building a keyword search, and that will systematically miss responses where different people use different language for the same idea. Claude Opus 4.7 looks like it could work better, with the large asterisk that we have not yet tested it on contemporaneous events. The response-level patterns — panelists coded more accurately, longer and multi-topic answers coded less accurately, attentive respondents coded less accurately — suggest that the quality of automated coding depends as much on how the question is asked and who is answering as on which model you choose.
We would offer three takeaways for anyone considering this approach. First, do not treat LLM coding of open-ends as comprehension; treat it as a keyword search, and expect it to do well on proper-noun categories and poorly on conceptual ones. Second, validate against human coding before trusting the output, and pay attention to whether errors correlate with respondent characteristics, because differential accuracy is a bias problem, not just a noise problem. Third, design the open-end with automated coding in mind — shorter, more concrete prompts that steer respondents toward nameable answers will be coded more reliably than open invitations that produce long, multi-topic replies.
We are continuing this work: testing contemporaneous Claude coding against open-source and commercial alternatives, experimentally limiting response length, and trying more concrete open-ends such as a media-consumption question. If you are running experiments on coding open-ends with LLMs, or thinking about it, we would love to compare notes. Reach out at info@survey160.com so we can get better together.